

The fundamental challenge of natural language processing (NLP) is resolution of the ambiguity that is present in the meaning of and intent carried by natural language. Ambiguity occurs at multiple levels of language understanding, as depicted below:

To resolve ambiguity within a text, algorithms use knowledge from the context within which the text appears. For example, the presence of the sentence “I visited the zoo.” before the sentence “I saw a bat” can be used to conclude that bat represents an animal and not a wooden club.
While in many situations neighboring text is sufficient for reducing ambiguity, typically it is not sufficient when dealing with text from specialized domains. Processing domain-specific text requires an understanding of a large number of domain-specific concepts and processes that NLP algorithms cannot glean from neighboring text alone.
As an example, in Title Insurance and Settlement domain, an algorithm may require an understanding of concepts like:
- A 1003 is a form one uses to apply for mortgages
- Balancing is a processing step on the path to closing a real estate transaction
- When Balancing is completed, one next processing step could be the Release of Funds
- This is where domain-specific knowledge bases come in.
Domain-specific knowledge bases capture domain knowledge that NLP algorithms need to correctly interpret domain-specific text.
Depending on the use case, knowledge housed in a knowledge base could be of a specific type or of multiple types.
Traditionally, knowledge bases have been modeled as graph-based ontologies and added as one of the components in text processing pipelines. However, with the advent of Transformer-based language models, like BERT and GPT-2, there has been research and evaluation[1][2] on the type and quality of knowledge inherent in a trained language model.
Note: Statistical language models are probability distributions over sequences of words. The probability distributions are used to predict the most likely word(s) at a position in a text sequence, given preceding and/or succeeding words of the sequence.
A favorable result of such evaluation can make a case for dropping the separate knowledge base component from text processing pipelines to significantly reduce their complexity. Focusing on this idea, this blog post describes the challenges of graph-based knowledge bases and provides an evaluation of domain knowledge present in language models that have been fine-tuned on text from the title and settlement domain.
Types of knowledge expected in a knowledge base
To evaluate a knowledge base, one needs to test it on all types of knowledge that will be required to process text from the domain. Below is the list of select knowledge types that might be required in a knowledge base for domain-specific text processing:
1. Knowledge of business-specific entities, like artifacts, events, and actors
- Examples: documents, file, notary, and specific types of documents, e.g. 1003
- This type of knowledge enables definition and application of entity-level domain attributes. For example, if a document is identified, one knows that it can be shared and it has a page count attribute
2. Knowledge of entity attributes
- Example: residential refinance borrowers have an attribute, e.g. marital status
- This type of knowledge defines attributes associated with an entity type and facilitates interpretation of text and extraction of information
3. Knowledge of relationships amongst and between entities
- Example: closing disclosure is part of a lender package
- This type of knowledge helps evaluate impact on parent entities when child entities are modified
4. Knowledge of how it all fits together into business processes
- Example: finding a notary leads to scheduling a closing appointment
- This type of knowledge dictates the next action given information about the business process state
Depending on the business domain and use case, more types of knowledge may be required in the knowledge base.
Typical knowledge base design, lifecycle, and costs
To create a knowledge base, one needs to define the knowledge that would be present in the knowledge base. Depending on the knowledge base, this is done either completely by human experts, for example WordNet[3], or by automated algorithms that may or may not build upon human-defined knowledge, for example YAGO[4].
Knowledge, once defined, is modeled in knowledge bases as graphs or ontologies. Concepts like classes and individuals are modeled as nodes, and relations amongst them are modeled as edges of graphs. Classes express concepts like documents and events. Individuals express instances of classes, for example 1003s, closing disclosures, and deeds all being instances of class documents. Edges capture relationships between classes and individuals. Examples of relationships that edges capture are is-type-of, is-instance-of, and has-attribute. In the example below, a directed edge between 1003 and Document is used to capture the knowledge that a 1003 is a type of Document.

The ontology or graph itself is represented using knowledge representation languages like RDF, RDFS, and OWL, and stored in formats like XML.
There are many popular knowledge bases — like YAGO and Concept Net — that model a variety of relationships this way. They often pick up entities to model from other knowledge bases like Wikipedia and WordNet.
Once a knowledge base is ready, different NLP models use different ways to incorporate it in their pipelines. Options include:
- Using entity type information present in the knowledge base, to replace or augment entity occurrences in text
- Using features created from graph-based measures, like distance between nodes of entities mentioned in text, as features in a model[5]
- More advanced methods that tie in feature extraction from the graph into the backpropagation and loss optimization loop through techniques like graph embeddings and LSTM-based feature extraction[6]
These methods are non-trivial and require significant effort to invent and incorporate in training and application phases.
Based on the above, it is clear that knowledge bases, in the form of graphs and ontologies, are costly in terms of time, effort, and money, especially when human experts are involved.
Evaluating if Transformer-based language models carry built-in domain knowledge bases
Motivation
Since creating and incorporating ontology-based knowledge bases is costly, a better alternative is always welcomed.
In recent years, Transformer-based language models like BERT and GPT-2 have dominated the leaderboards across NLP competitions, tasks, and benchmarks. Impressively, they have achieved this with:
- A single model forming the end-to-end pipeline (in contrast to multi-model text processing pipelines)
- Minimal fine-tuning of pre-trained models
- Use of a common base model across multiple tasks
Given such success and ease of use, it would be ideal if a fine-tuned version of these models incorporated domain knowledge within them. If so, one can:
- Skip the high costs of creating a knowledge base
- Drop the separate knowledge base component and simplify the multi-model text processing pipeline
- Retain the benefits of having a knowledge base, as knowledge captured within the language model will automatically come into play while using the model for downstream tasks
- Get an additional boost of broader world knowledge built into the language model during its pre-training phase
Evaluation methodology
To evaluate, we fine tuned a roBERTa-base and a gpt2-medium model (both from Hugging Face) on internal company data and explored the knowledge captured in them. The methodology used to evaluate the models was:
- Decide on a type of knowledge that needs to be evaluated. Example: is-a-type-of relationships
- Generate specific instances of knowledge type to test presence of knowledge. Example: 1003 is a type of document.
- Modify the knowledge instance by either masking the word or adding an additional fill-in-the-blank kind of question at the end of the instance. Example: 1003 is a type of _.
- Ask the model to fill in the blank and evaluate the answer.
Note, there are other methodologies that can be used depending on the type of knowledge that needs to be tested.
Sample model inputs and outputs
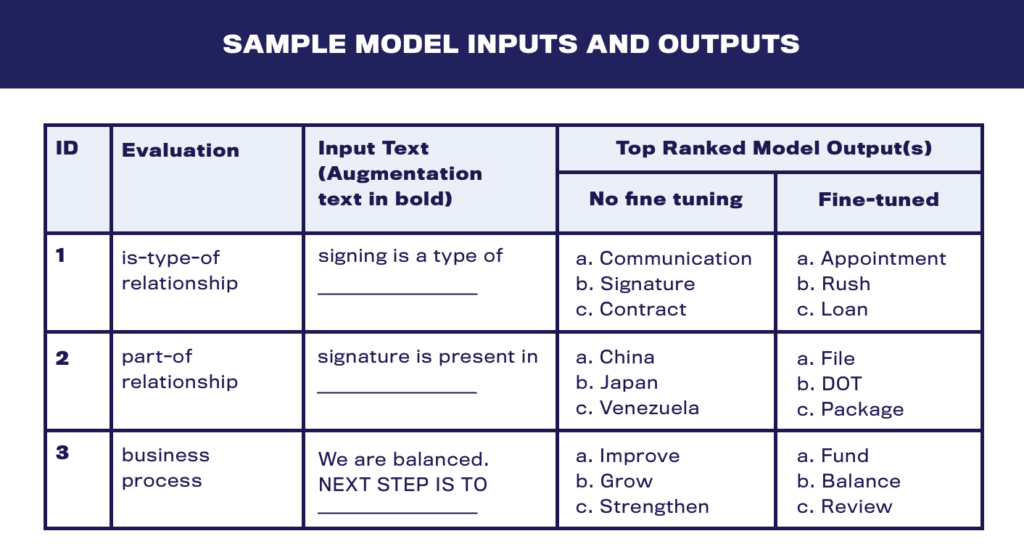
Select findings and analysis
RoBERTa captured multiple types of relationships and was able to automatically extend concepts learnt to new unseen entity instances
Is-type-of relationship:
- Pre-Fine Tuning: Citibank is a type of bank .
- Post-Fine Tuning: Citibank is a type of lender .
Note, Citibank was not present in the dataset at all. It seems the model learned that banks play the role of lenders in the title insurance and settlement business. It then applied that learning to banks it knew from its pre-training.
Entity-attribute relationship:
- Post-fine tuning: Notary’s _ is _
Top values suggested for the first blank: name, information, email, contact, info, address, confirmation, schedule, number
Entity-associated-with-action relationship
- __ needs to be changed
Values suggested for blank are: password, title, this, nothing, CD, amount, fee, it, name
While there were a few examples where model results were not as convincing as the above examples, for most examples they were. It seems the language model nicely captures is-type-of, entity-attribute, and entity-associated-action relationships.
Knowledge output by the model, while mostly sensible, was not always informative, useful or what was ideally desired
Part-of relationship
- Lender package is made up of pages .
Other top answers were: two, documents, trust, boxes
For the above example, while answers like pages and documents are not wrong, they are not very useful either. Answers like closing disclosure, 1003, or signature affidavit, would have been more informative. Similarly in example 7., answers like nothing and this are not informative. These non-useful answers were found across various evaluations and could roughly be classified into the following categories: pronouns, interrogative words like ‘what’, punctuations, and words repeated with case variations.
Models developed a good understanding of business process, but required intelligent external input to make use of that understanding
Business process understanding
Fine-tuned RoBERTa:
9.
- Input: We are balanced.
- Augmentation: Please provide __
- Model output (for next two words): payoff statement
Fine-tuned gpt2-medium:
10.
- Input: Loan amount is wrong.
- Augmentation: Please provide __
- Model output: updated fee sheet with correct loan amount
11.
- Input: Loan amount is wrong.
- Augmentation: Please obtain __
- Model output: deed correcting vesting
12.
- Input: Notary is available.
- Augmentation: Next step is __
- Model output: signing
Note, in examples 9., 10. and 12. — when provided with a good augmentation — the model was able to deliver a sensible answer. In contrast, in example 11., where the augmentation wasn’t typical, the model did not generate an acceptable answer. This may turn out to be an issue if downstream tasks do not have an easy way to provide the required text augmentation.
Beyond language model’s built-in knowledge base
While this blog primarily focused on evaluating language models’ built-in knowledge bases, if it is required and not cost-prohibitive, one may want to consider an approach similar to COMeT[7]. COMeT fine-tunes a pre-trained language model on an existing knowledge base to predict known and new knowledge base relationships.
Training on an existing knowledge base enriches the model with wider and more accurate knowledge than what was contained in the original knowledge base or the pre-trained language model. While discussion of COMeT’s approach is out of scope for this blog, an online demo of COMeT trained on ATOMIC[8] and ConceptNet[9] could be found here.
Takeaway
Based on the above analysis we believe that language models — once fine tuned — do hold rich domain knowledge within them. However, there are challenges, like right augmentation text and identifying the more informative model outputs in making direct use of the knowledge.
References
- [1] Petroni, Fabio, et al. “Language Models as Knowledge Bases?” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
- [2] Davison, Joe, Joshua Feldman, and Alexander M. Rush. “Commonsense knowledge mining from pretrained models.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
- [3] Princeton University. “About WordNet.” WordNet. Princeton University. 2010.
- [4] Suchanek, Fabian M., Gjergji Kasneci, and Gerhard Weikum. “Yago: a core of semantic knowledge.” Proceedings of the 16th International Conference on World Wide Web. 2007.
- [5] Xia, Jiangnan, Chen Wu, and Ming Yan. “Incorporating Relation Knowledge into Commonsense Reading Comprehension with Multi-task Learning.” Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019.
- [6] Lin, Bill Yuchen, et al. “Kagnet: Knowledge-aware graph networks for commonsense reasoning.” arXiv preprint arXiv:1909.02151. 2019.
- [7] Bosselut, Antoine, et al. “COMET: Commonsense Transformers for Knowledge Graph Construction.” Association for Computational Linguistics (ACL). 2019.
- [8] Sap, Maarten, et al. “Atomic: An atlas of machine commonsense for if-then reasoning.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
- [9] Speer, Robyn, Joshua Chin, and Catherine Havasi. “ConceptNet 5.5: an open multilingual graph of general knowledge.” Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. 2017.