

Information extraction is the process of extracting structured information from free-form textual data. It is one of the most promising applications of natural language processing (NLP). In this blog, I will discuss why information extraction is challenging in some scenarios and how to design a deep learning model for information extraction that is right-sized for your use case. After reading it, you should be able to understand some basic concepts about information extraction. If you have a background in data science and neural networks, you should be able to make faster progress towards creating a customized information extractor for your own business problem.
To have a better understanding of the problem we are going to solve, let’s first look at an example. At Doma, we want to extract several important fields from emails, such as property address, borrower name, and loan number. Can we design a rule-based method to extract these fields? Sometimes it works when there is not too much variation. However, information extraction is often too challenging for a rule system due to the large diversity of some fields and high dependence on the context.
Here is an email example:
Hi, please open title for the following
- Escrow No.: 00000-ME
- Sales Rep: XXXX XXXX
- Borrowers: XXXX XXXX and XXXX XXXX
The subject address will be 1000 Golden Street, Fremont, CA 94000
Please note that our office is closed. Please do not come to the office to pick up or drop off checks or other documents. I’m happy to accommodate your delivery or receipt of these items in another way.
XXXX XXXX
Sincerely,
Escrow Assistant at ABC Escrow, Inc.
Address: 2000 Main Street, Ste 200, San Jose CA 95000
Phone: 800.000.0000
Email: aaabbb@abcd.com
Your review helps others like you. Click here to leave us a review!
In this example, the property address of interest is marked as red. There is another address (marked as green), which is the address of an escrow assistant and is not relevant for extraction. The algorithm should be able to distinguish the property address from other addresses. As human being, we know the red address is a property address because we can understand the meaning of the context like ‘the subject address will be’. Obviously, context plays a big role in making decisions. But how can a machine do it?
Recently, deep learning models with natural language understanding capability have been developed. BERT [1] is one of the most popular one among them and it is also a common framework for doing information extraction. In the following sections, I will discuss how to extract information with BERT and you will see how BERT can leverage the context to make decisions.
BERT Model
BERT stands for Bidirectional Encoder Representations from Transformers. It is a pre-trained model and uses the attention mechanism [2] to divide English language sentences into pieces known as “tokens.” One way to develop an intuitive understanding of the mechanism is to think of it as permitting a specific token to selectively focus on other tokens in the sequence according to their correlations. In this way, tokens gain information from other tokens with weights determined by the attention mechanism. The resulting algorithm can learn not only the syntactic (i.e., grammar-related) but also the semantic (i.e., meaning-related) aspects of natural language. As a deep learning neural network, the BERT model can be extended with one additional output layer to create models for a wide range of downstream NLP tasks.
Among these tasks, question answering (QA) and named entity recognition (NER) can potentially be applied for information extraction because they can provide token-level classification results. Therefore, we decided to investigate BERT-based QA model and BERT-based NER model for property address extraction from emails. The input of a traditional QA model usually has two segments: a question and a paragraph. The paragraph is used to extract the answer. The two segments are separated by a special token [SEP] and segment embeddings will help the model distinguish different segments.
Certain assumptions can help simplify our design. In our use case, we only have one attribute to extract which is the property address. In addition, an email includes a subject and a body and distinguishing these two parts can provide additional information for the model to make better predictions. For example, an address in the subject is more likely to be a property address compared with an address in the body. These are examples of how we modified the input of the QA model to accommodate to our specific scenario.
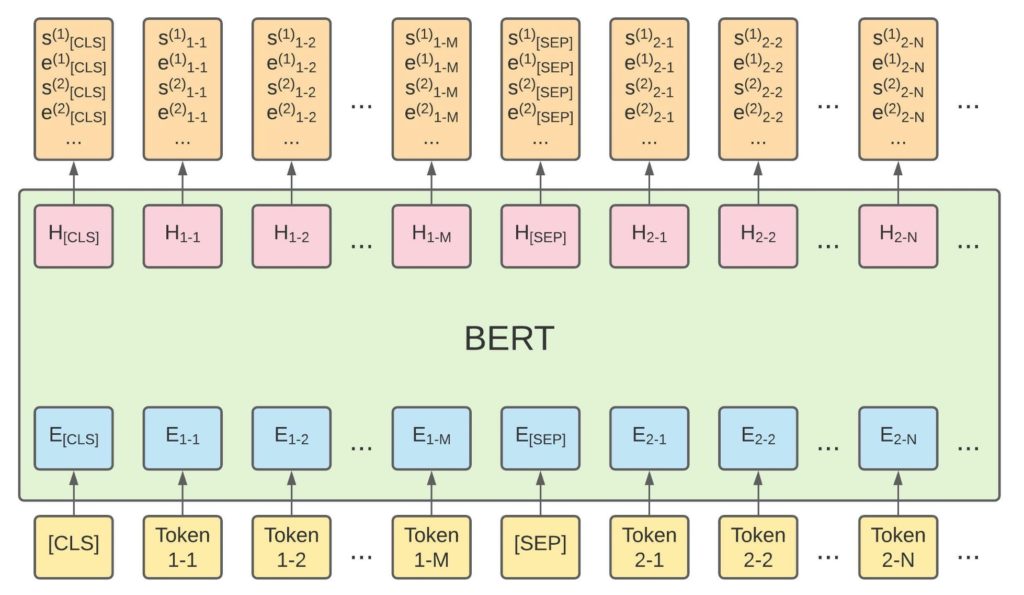
Figure 1: Modified BERT QA model architecture.
The modified architecture of the BERT-based QA model is shown in Figure 1. Our modified input still has two segments, but we assign subjects to the first segment and bodies to the second segment. There is no segment for questions anymore. The output of a QA model are multiple parallel binary classification layers. For each token, the model will predict the probabilities of that token to be the start position and the end position of the fields to extract. Therefore, we can get the most probable start and end positions in the input sequence, which gives us a span of the answers. If there is only one field to extract (e.g., property address) then there are two binary classifiers which connect to the last hidden states of the BERT model for the start and end positions of the specific field. To generalize it, we can even have more segments in the input sequence and each pair of adjacent segments should be separated by [SEP] to take advantage of segment embeddings. Figure 2 shows an example of a property address extraction model. According to the start and end logits, the most probable start position is at ‘100’ and the most probable end position is at ‘94000’, so the predicted span is ‘100 Golden Street, Fremont, CA 94000’.

It is possible that there is no entity in some of the instances. To handle this unanswerable question issue, we can set the start and end positions at the first token ([CLS]) of the token sequence for the unanswerable questions in the training data. In the inference stage, the answer score is defined as the sum of the best start and end logits. The null score is defined as the sum of the start and end logits associated with the [CLS] token. We can use the difference between answer score and null score to determine whether the question is answerable or not.
The input sequence of a conventional NER model only has one segment, but we can also have multiple segments to add segment embeddings for different segments, (shown in Figure 3) which is similar to the input schema of the modified QA model. The only difference between the modified NER model and the QA model is the output layer. For the NER model, we also have to add a token-level classifier, but it is a multi-class classifier to classify multiple NER tags instead of a binary classifier which is used in the QA model. The output example of an NER model is shown in Figure 4. For each token, the model can predict an NER tag.
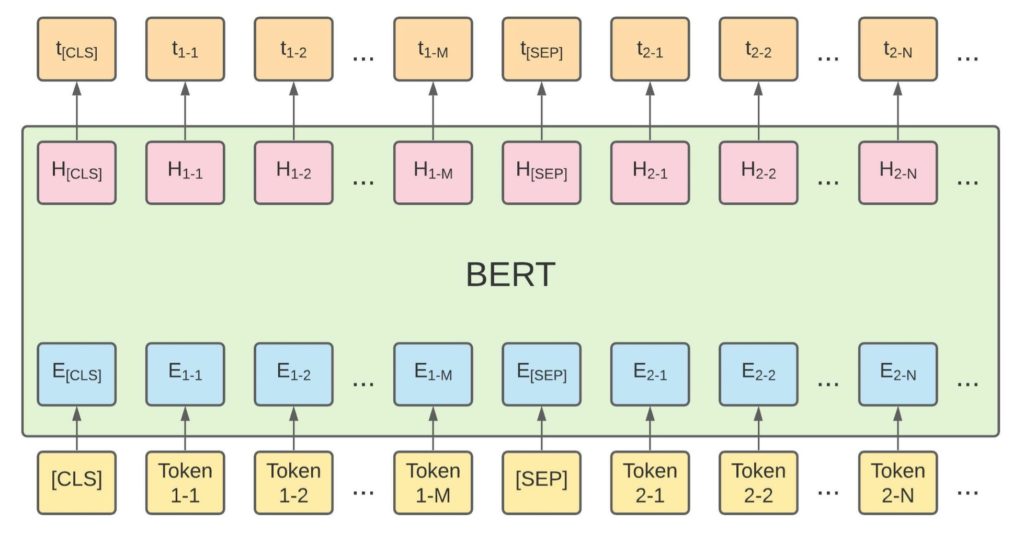
The choice between QA model and NER model depends on the requirements of your project. The limitation of a QA model is that it can only extract one entity per label. For example, it can only extract one property address with the best start and end logits. However, it is possible to have multiple property addresses and we want to extract all of them. To handle it, an additional post-processing step should be developed. For example, we can keep track of the top N start and end positions as candidates and use some heuristics to select from them. One drawback of the NER model is that each token is classified separately so there is no guarantee of a continuous entity. For example, in the instance shown in Figure 4, it is possible that the token ‘Fremont’ is predicted as O (meaning it is not relevant), which split the ground truth result into two pieces. Although the BERT embeddings can leverage information from the context of each token bidirectionally, this issue occurs quite frequently in practice. Therefore, a post-processing step is needed to join the entity segments and provide clean extracted results.

Evaluation and Hyperparameter Tuning
To measure the performance of different models, we need an all-purpose evaluation method. No matter which models we use, after post-processing, we can get a set of detected entities and a set of ground truth entities for each instance. Precision and recall can be used as evaluation metrics to distinguish the impact of false positives and false negatives. F1 score, which is the harmonic mean of the precision and recall, can be used to show the overall performance of the model.
One frequently occurring question is how to determine true positives when the entities are spans of words. The straightforward approach is to use exact match. If a predicted entity can be exactly matched with an entity in the ground truth entity set, then it is treated as a true positive. If you think it is too picky to only take exact match into consideration, we can introduce a string similarity/distance metric as a reference to handle partial match, such as Jaccard similarity (intersection over union), Levenshtein distance (edit distance), etc. Similarity/distance can be calculated in either character level or word level. Assuming we are using Jaccard similarity, a cutoff value is needed for evaluation. For a given predicted entity, if there is a ground truth entity whose similarity with the predicted entity is greater than the cutoff value, then the predicted entity should be treated as a true positive for precision calculation. Otherwise, it is a false positive. Similarly, the true positives and false negatives can also be determined to calculate the recall. The similarity cutoff represents what quality you require your model output to have. The higher the similarity cutoff is, the higher standard you set for the model. For example, the Jaccard similarity is between 0 and 1. If you set its cutoff value to 1, then it is the same as the exact match.
Different projects have different preferences on precision and recall. After you obtain a trained model, you can tune some hyperparameters to achieve the optimal combination of precision and recall for reference. For example, in the QA model, the difference between the answer score and null score is a hyperparameter to determine whether to output an answer span for a label. Let’s name it null threshold. If we set a higher null threshold, then the model prefers to output more null answers, so the precision will increase, and recall will decrease. By tuning null threshold, you can get an optimal F1 score, a higher precision with acceptable recall or a higher recall with acceptable precision.
Conclusions
BERT-based deep learning models have been demonstrated to be a powerful tool for information extraction. Instead of using the architecture proposed by the original paper directly, you can easily customize the input and output layer to align with your specific purpose. Although we only use BERT as the pre-trained encoder in this blog, you can replace it with other variants of BERT such as RoBERTa [3] and XLNet [4], which have been reported to outperform BERT on some downstream tasks. With the help of some open-source libraries, like Hugging Face and PyTorch, you can easily experiment with several different strategies and find the most suitable solution to your problem.
Table 1: List of notations used in this blog
| Symbol | Description |
| dhidden | The hidden size of a model. For BERT, it is 768. |
| Ei-j | The input embedding of the jth token in the ith segment. Dimension: dhidden. |
| Hi-j | The last hidden state of the jth token in the ith segment. Dimension: dhidden. |
| s(k)i-j | The start logit of the kth class at the jth token in the ith segment. |
| e(k)i-j | The end logit of the kth class at the jth token in the ith segment. |
| ti-j | The NER tag at the jth token in the ith segment. |
References:
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805, 2018.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. arXiv:1706.03762, 2017.
[3] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692, 2019.
[4] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv:1906.08237, 2019.