

Machine learning can deliver an incredible amount of value to business. Doma is a prime example of this, with data science models powering a complete transformation of the title and escrow business. However, one of the most overlooked (but crucial) elements of an effective data analytics strategy is data infrastructure. While data science can answer questions like “How can we improve this business process?,” data engineering can answer: “How do we surface the impact of the improvements to the business?”
History
I joined Doma late last year with a mandate to overhaul the existing data infrastructure, which involved me playing the parts of data architect and developer, in addition to people management.
Only months before I started, Doma – a fairly early-stage startup – acquired the North American Title companies – a pair of established, successful enterprises. The resulting data landscape was what might be expected from such a merger: many AWS RDS databases spun up for specific purposes but lacking formal administrators for the former entity, and an existing architecture firmly planted in the Microsoft SQL Server ecosystem for the latter.
Decisions, decisions
Having worked on building out a data lake from scratch at my previous role, I saw the potential value the principles associated with data lake architectures could bring to the redesign of Doma’s data architecture.
A highlight of some of the principles I thought would be most powerful are:
- Decoupling of storage and compute
- Support for all types of data, structured or unstructured
- Allowing for rapid data ingestion compared to traditional data warehousing
However, these advantages also bring challenges. When compute and storage are decoupled, an architect might suffer from an abundance of choice. For storage, does one opt for a potentially more performant (and costly) choice like Hadoop Distributed File System (HDFS) – a highly reliable and scalable choice like cloud object storage – or some other, perhaps managed solution? For compute (specifically a query engine) which method of delivering SQL against big data – for example, Hive LLAP or Presto) – best serves the organization’s needs?
Beyond architectural choices, the engineering effort involved in setting up a data architecture system of this kind definitely is not trivial, even when leveraging managed versions of these tools as offered by various cloud service providers.
I mulled these choices over and weighed the potential up-front and longer term overhead a data lake solution might incur against the organization’s current needs. As a relatively early-stage startup, our data needs were more to ensure integrity and quality of the data as presented to users, rather than optimize for frictionless ingestion of data at scale.
A new direction
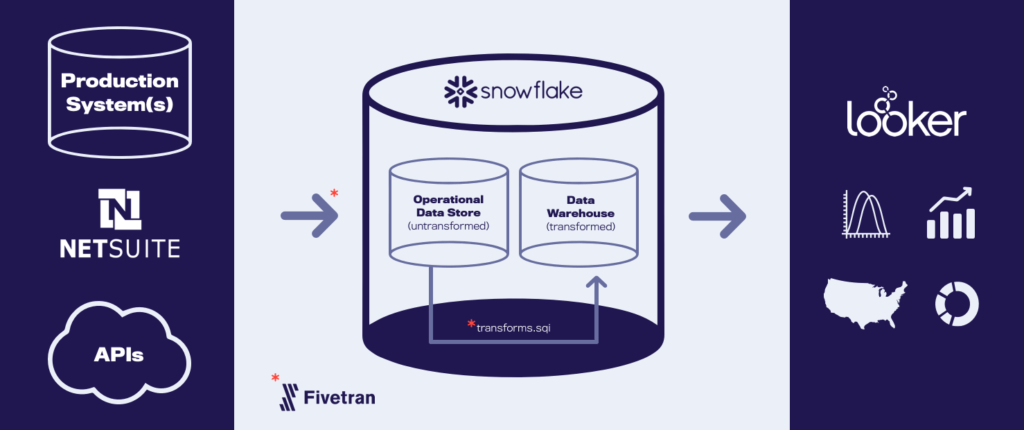
After some consideration, I was more and more drawn to a solution like Snowflake. Snowflake is a cloud-native data warehouse that offers many of the benefits one would desire in a data lake architecture: decoupled storage and compute, support for structured and semi-structured data, and plays nicely with open-source streaming and distributed compute tools like Kafka and Spark, respectively, if and when the organization’s data needs focus more on ingestion of data at scale. Beyond that, it is a full-fledged data warehouse platform with all the benefits that offers: ACID transactions, schema validation, built-in mechanisms for role-based permissioning, and much faster query latency – the last of which is especially important for business users.
Now that the platform has been chosen, more choices were to be made: How do we move data from production systems to Snowflake and how do we properly manage any transformations along the way? This process is probably better known to readers as extract, transform, and load (ETL). Alternatively, Snowflake’s design lends itself to organizations looking to follow an extract, load, and transform (ELT) pattern, where data is extracted in a near-raw format from source systems, loaded into the destination, and transformed within Snowflake itself, leveraging larger virtual warehouses for more compute-intensive transformations.
There are many options that can be mapped to each of the steps in an ELT pattern – some open-source and some managed solutions. The option we eventually settled on is Fivetran. We’ve found Fivetran to be a powerful tool to replicate company data, whether it resides in a transactional RDBMS or any one of a number of SaaS applications, seamlessly managing the API and format translation required to move information where it needs to go.
That choice solved the E and L steps of the process, but what about the T? One of Fivetran’s newest features is Transformations, which allows users to schedule and orchestrate transformations of data once it lands in your data warehouse. And GitHub integrations ensure tracking data versioning and lineage. While the scheduling of the transformations is handled by Fivetran, the logic of the transformations are written in SQL and executed in Snowflake.
One of our team’s principles is designing our architecture in such a way that tools can be swapped out for one another.
The majority of data users consume information almost entirely via a business intelligence tool. At Doma, this tool is Looker. Once the data has been transformed into a ready-to-use state, it is ready to be presented to business users through Looker. In addition to providing visualization tools, Looker also provides a powerful abstraction layer known as LookML, with which BI developers can define views (roughly equivalent to relational tables) and models (the data model where views are joined together). Using a point-and-click interface, end-users interact with the data models defined in LookML, which Looker translates into what are often quite complex SQL queries, to produce visualizations and dashboards.
Our Architecture
The end result of all the choices described above is the current data architecture, given below:
Looking Forward
As for future changes to our data stack, we’ll constantly evaluate options as our business needs change. For example, we’re considering augmenting a few data workflows with Airflow, adding to what we’re already doing with Fivetran.
Looking to the mid to long-term, we will also augment the existing data architecture with a data lake to house and curate unstructured data – like text and images – that is used to power our data science models. This will exist in parallel with a more defined data warehouse model, such that different use cases can be supported with a single platform. We’ll have to revisit the same challenges outlined above but I believe we’re better positioned to build more rapidly with our existing cloud-native data stack as a foundation.

